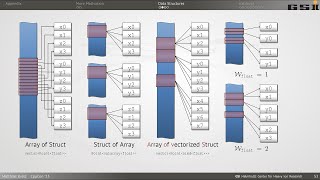
Overview of Matrix Multiplication Deep Dive Cache Blocking Simd Parallelization Aliaksei Sala Cppcon GHctcSBd6Z4
Looking for Matrix Multiplication Deep Dive Cache Blocking Simd Parallelization Aliaksei Sala Cppcon GHctcSBd6Z4 details? We've researched comprehensive information, latest updates, and exclusive insights for Matrix Multiplication Deep Dive Cache Blocking Simd Parallelization Aliaksei Sala Cppcon GHctcSBd6Z4. Discover the complete Details breakdown, history, and detailed profile.
Результат моделирования кеш-памяти на задаче блочного матричного умножения. Размер матрицы: 256х256. Размер ... Okay so i hope you can see my screen so i have i have this access sequence to a Join the k1 programming language discord: on X: x.com/kolemannix K1: ...
Core Information
Explore the primary sources for Matrix Multiplication Deep Dive Cache Blocking Simd Parallelization Aliaksei Sala Cppcon GHctcSBd6Z4.
Latest News
Stay updated on Matrix Multiplication Deep Dive Cache Blocking Simd Parallelization Aliaksei Sala Cppcon GHctcSBd6Z4's newest achievements.
Must Know Technique in GPU Computing | Episode 4: Tiled Matrix Multiplication in CUDA C
Matrix Operations with Cilk SDK optimization.avi
Matrix multiply with cache blocking, fast forward
MMA Matrix Multiplication (Inclusive cache model)
The Hardware/Software Interface || 06 Cache Friendly Code 12 19
L4c How To Do Cache-Blocking Of Matrix Multiplication and CONV
CUDA Crash Course: Cache Tiled Matrix Multiplication
Dividing N by N Matrix into Tiles - Intro to Parallel Programming
Naive matrix multiply, fast forward
C++ cache locality and branch predictability
std::simd: How to Express Inherent Parallelism Efficiently Via Data-parallel Types - Matthias Kretz
How I deal with recursive data without blowing the stack
Deep Dive
Data is compiled from public records and verified media reports.
Last Updated: June 23, 2026
Future Outlook
For 2026, Matrix Multiplication Deep Dive Cache Blocking Simd Parallelization Aliaksei Sala Cppcon GHctcSBd6Z4 remains one of the most searched-for information profiles. Check back for the newest reports.
Disclaimer: Disclaimer: Details details are based on publicly available data, media reports, and general analysis. Actual facts may vary.