Kv Cache Explained G3Fqq6cqOrc
Safe & Secure Download - Verified by Melio Educational ERP
Kv Cache Explained G3Fqq6cqOrc Information Guide
Overview of Kv Cache Explained G3Fqq6cqOrc

Try Voice Writer - speak your thoughts and let AI handle the grammar: The To produce one word, a language model has to look back at every word that came before it and run the entire stack of attention ... Ever wonder how even the largest frontier LLMs are able to respond so quickly in conversations? In this short video, Harrison Chu ... Don't like the Sound Effect?:* *LLM Training Playlist:* ... Preparing for AI, ML, or LLM infrastructure interviews? Practice real interview-style questions here: Don't miss out! Join us at our next KubeCon + CloudNativeCon events in Mumbai, India (18-19 June, 2026), Yokohama, Japan ...
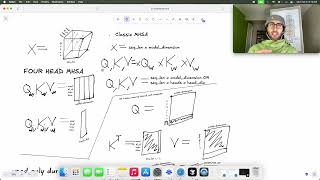
00:00 Attention Is Geometry 00:53 TurboQuant Introduction 01:02 Two Problems with Standard Quantization 01:54 Hadamard ... A visual deep-dive into how attention works in modern LLMs — from embeddings and Q, K, V projections to Your AI model secretly redoes the SAME math millions of times — every single time it replies to you. Ever wonder why ChatGPT ... Running a 7B model on a 1M token context needs 128GB of VRAM — that's 9× the size of the model itself. This video unpacks ...
Core Information

Recent Updates












Detailed Analysis
Data is compiled from public records and verified media reports.
Last Updated: June 23, 2026
Summary

Disclaimer: Disclaimer: Details details are based on publicly available data, media reports, and general analysis. Actual facts may vary.
